
El modelo de lenguaje Switch Transformer de Google Brain incluye la friolera de 1,6 billones de parámetros y, al mismo tiempo, controla eficazmente el coste computacional. El modelo logró una aceleración de preentrenamiento 4 veces superior a una línea de base T5-XXL fuertemente ajustada.
(Synced)-En la búsqueda continua de algo más grande y mejor, los investigadores de Google Brain han escalado su modelo de lenguaje Switch Transformer recientemente propuesto a la friolera de 1,6 billones de parámetros mientras mantienen los costos computacionales bajo control. El equipo simplificó el algoritmo de enrutamiento de Mixture of Experts (MoE) para combinar de manera eficiente los datos, el modelo y el paralelismo de expertos y habilitar este «número escandaloso de parámetros» al tiempo que logra una aceleración cuatro veces superior a la del preentrenamiento sobre una línea de base T5-XXL fuertemente ajustada (Google’s modelo de lenguaje anteriormente más grande).
Los gigantescos modelos de lenguaje se presentan en el documento Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity .

Aunque muchas arquitecturas de aprendizaje profundo recientes y más simples han superado el rendimiento de algoritmos más complicados, estas ganancias de rendimiento han venido con enormes presupuestos computacionales, enormes conjuntos de datos y grandes recuentos de parámetros. El equipo señala que los modelos de aprendizaje profundo tienden a reutilizar los mismos parámetros para todas las entradas, mientras que los modelos de mezcla de expertos (MoE), en cambio, usan parámetros diferentes. Centraron su atención en el entrenamiento a gran escala de modelos de lenguaje utilizando solo un subconjunto de los pesos (parámetros) de la red neuronal para cada ejemplo entrante, y la escasez proviene de una técnica recientemente propuesta para simplificar el paradigma de MoE.
En el contexto de las arquitecturas de aprendizaje profundo, el algoritmo de enrutamiento del MoE permite modelos para combinar la salida de varias redes de expertos, donde cada una de las redes de expertos se especializa en una parte diferente del espacio de entrada. De esta manera , una red de puertas aprendidas combina los resultados de las redes de expertos para producir un resultado final. «Esto (MoE) dio como resultado resultados de vanguardia en el modelado de idiomas y los puntos de referencia de traducción automática», explican los investigadores. Una de las contribuciones clave del estudio es la reducción de los costos computacionales y de comunicación del paradigma simplificado de MoE. A diferencia de las estrategias de MoE previamente probadas que se enrutan a más de una red de expertos para permitir gradientes no triviales en las funciones de enrutamiento, los modelos propuestos utilizan solo un experto.

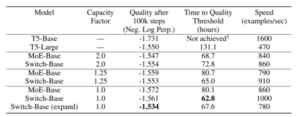
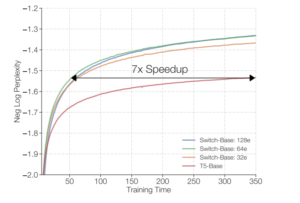
El equipo dice que la técnica simplificada propuesta garantiza que los pesos del modelo aumenten con la cantidad de dispositivos, mientras se mantiene una memoria manejable y una huella computacional en cada dispositivo. Switch Transformer preentrenado en Colossal Clean Crawled Corpus (C4) con 32 núcleos de TPU consume menos computación y supera tanto a los modelos densos cuidadosamente ajustados como a los modelos MoE.
En experimentos, Switch Transformer mejoró el modelo multilingüe basado en T5 (mT5)en 101 idiomas diferentes en la variante multilingüe del conjunto de datos Common Crawl (mC4). Switch Transformer también logró una aceleración media previa al entrenamiento sobre la línea de base mT5, con 91 por ciento de los 101 idiomas experimentando aceleraciones cuatro veces mayores. Además, el equipo demostró la posibilidad de impulsar la escala actual de modelos de lenguaje entrenando previamente a Switch Transformer con 1.6 billones de parámetros en una cuarta parte del tiempo requerido para el modelo T5-XXL.

El documento Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity está en arXiv.

