
Microscope y Lucid Library son nuevas adiciones a la pila de código abierto de OpenAI.
Por Jesús Rodríguez (médium.com)
La interpretabilidad es uno de los aspectos más desafiantes del espacio de aprendizaje profundo. Imagine comprender una red neuronal con cientos de miles de neuronas distribuidas en miles de capas ocultas. La naturaleza interconectada y compleja de la mayoría de las redes neuronales profundas las hace inadecuadas para las herramientas de depuración tradicionales. Como resultado, los científicos de datos a menudo se basan en técnicas de visualización que les ayudan a comprender cómo las redes neuronales toman decisiones, lo que se convierte en un desafío constante. Para avanzar en esta área, OpenAI acaba de presentar Microscope y Lucid Library que permiten la visualización de neuronas dentro de una red neuronal.
La interpretabilidad es una propiedad deseable en las soluciones de redes neuronales profundas hasta que necesite sacrificar otros aspectos como la precisión. La fricción entre las capacidades de interpretación y precisión de los modelos de aprendizaje profundo es la fricción entre poder realizar tareas de conocimiento complejas y comprender cómo se lograron esas tareas. Conocimiento versus control, desempeño versus responsabilidad, eficiencia versus simplicidad… elija su dilema favorito y todos se pueden explicar al equilibrar las compensaciones entre precisión e interpretabilidad. Muchas técnicas de aprendizaje profundo son de naturaleza compleja y, aunque resultan muy precisas en muchos escenarios, pueden volverse increíblemente difíciles de interpretar. Todos los modelos de aprendizaje profundo tienen cierto grado de interpretabilidad, pero sus detalles dependen de algunos bloques de construcción clave.
Los componentes básicos de la interpretabilidad
Cuando se trata de modelos de aprendizaje profundo, la interpretabilidad no es un concepto único, sino una combinación de diferentes principios. En un artículo reciente , los investigadores de Google describieron lo que consideraron algunos de los pilares fundamentales de la interpretabilidad. El artículo presenta tres características fundamentales que hacen interpretable un modelo:
Comprender lo que hacen las capas ocultas: la mayor parte del conocimiento en un modelo de aprendizaje profundo se forma en las capas ocultas. Comprender la funcionalidad de las diferentes capas ocultas a nivel macro es fundamental para poder interpretar un modelo de aprendizaje profundo.
- Comprender cómo se activan los nodos: la clave para la interpretabilidad no es comprender la funcionalidad de las neuronas individuales en una red, sino más bien grupos de neuronas interconectadas que se activan juntas en la misma ubicación espacial. La segmentación de una red por grupos de neuronas interconectadas proporcionará un nivel más simple de abstracción para comprender su funcionalidad.
- Comprender cómo se forman los conceptos: comprender cómo la red neuronal profunda forma conceptos individuales que luego se pueden ensamblar en el resultado final es otro componente clave de la interpretabilidad.
Tomando prestada inspiración de las ciencias naturales
Definir los bloques de construcción clave de la interpretabilidad fue ciertamente un paso en la dirección correcta, pero está lejos de ser adoptado universalmente. Una de las pocas cosas en las que la mayoría de la comunidad de aprendizaje profundo está de acuerdo en cuanto a la interpretabilidad es que ni siquiera tenemos la definición correcta.
En ausencia de un consenso sólido en torno a la interpretabilidad, la respuesta podría depender de profundizar en nuestra comprensión del proceso de toma de decisiones en las redes neuronales. Ese enfoque parecía haber funcionado para muchas otras áreas de la ciencia. Por ejemplo, en una época en la que no había un acuerdo fundamental sobre la estructura de los organismos, la invención del microscopio permitió la visualización de células que catalizaron la revolución de la biología celular.
Quizás necesitemos un microscopio para redes neuronales.
Microscopio
OpenAI Microscope es una colección de visualizaciones de redes neuronales profundas comunes para facilitar su interpretación. Microscope facilita el análisis de las características que se forman dentro de estas redes neuronales, así como las conexiones entre sus neuronas.
Tomemos la famosa red neuronal AlexNet, que fue la entrada ganadora en ILSVRC 2012. Resuelve el problema de clasificación de imágenes donde la entrada es una imagen de una de 1000 clases diferentes (por ejemplo, gatos, perros, etc.) y la salida es una vector de 1000 números.
Con OpenAI Microscope, podemos seleccionar un conjunto de datos de muestra y visualizar la arquitectura central de AlexNet junto con el estado del proceso de clasificación de imágenes en cada capa.

Al seleccionar una capa específica (ej: conv5_1) Microscope presentará una visualización de las diferentes unidades ocultas en esa capa.
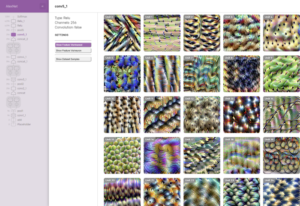
Después de seleccionar una capa, Microscope visualizará las características correspondientes, así como los elementos del conjunto de datos de entrenamiento que fueron relevantes para su formación.
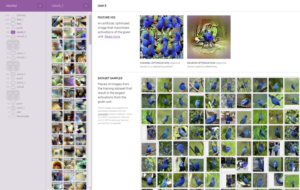
La navegación a través de Microscope puede ayudar a ilustrar cómo las visualizaciones inteligentes pueden ayudar a mejorar la interpretabilidad de redes neuronales profundas específicas. Para expandir la investigación inicial, OpenAI también abrió un marco para reutilizar algunos de los modelos de visualización existentes.
La biblioteca lúcida
La Biblioteca lúcida es un framework de código abierto para mejorar la interpretación de las redes neuronales profundas. La versión actual incluye todas las visualizaciones incluidas en Microscope.
Usar Lucid es extremadamente simple. El marco se puede instalar como un simple paquete de Python.
# Instalar Lucid! pip install –quiet lucid == 0.2.3#! pip install –quiet –upgrade-strategy = solo-si-es-necesario git + https: //github.com/tensorflow/lucid.git#% tensorflow_version solo funciona en colab% tensorflow_version 1.x# Importacionesimportar numpy como npimportar tensorflow como tfafirmar tf .__ versión __. startswith (‘1’)importar lucid.modelzoo.vision_models como modelosde lucid.misc.io import showimportar lucid.optvis.objectives como objetivosimportar lucid.optvis.param como paramimportar lucid.optvis.render como renderimportar lucid.optvis.transform como transform# ¡Vamos a importar un modelo de Lucid modelzoo!modelo = modelos.InceptionV1 ()model.load_graphdef ()
Visualizar una neurona usando Lucid es solo cuestión de llamar a la operación render_vis.
# ¡Visualizar una neurona es fácil!_ = render.render_vis (modelo, «mixed4a_pre_relu: 476»)
Además, Lucid produce diferentes tipos de visualización que pueden ayudar a interpretar capas y neuronas:
- Objetivos: ¿Qué quieres que visualice el modelo?
- Parametrización: ¿Cómo describe la imagen?
- Transformaciones: ¿A qué transformaciones desea que sea robusta su visualización?
El siguiente código visualizó una neurona con un objetivo específico.
# Visualicemos otra neurona usando un objetivo más explícito:obj = objetivos.canal («mixto4a_pre_relu», 465)_ = render.render_vis (modelo, obj)
Tanto Microscope como la biblioteca Lucid son mejoras importantes en el área de la interpretabilidad del modelo. La idea de comprender las características y las relaciones de las neuronas es fundamental para desarrollar nuestra comprensión de los modelos de aprendizaje profundo y versiones como Microscope y Lucid son un paso sólido en la dirección correcta.

