
OpenAI ha entrenado una red neuronal llamada DALL · E que crea imágenes a partir de leyendas de texto para una amplia gama de conceptos expresables en lenguaje natural.
En la última demostración del poder y el potencial del popular modelo de lenguaje grande GPT-3, los investigadores de OpenAI presentaron DALL · E , una red neuronal entrenada para crear imágenes a partir de leyendas de texto en una amplia gama de conceptos que se pueden expresar en lenguaje natural.
El GPT-3 de OpenAI, lanzado en junio pasado, mostró que las entradas del lenguaje natural podrían usarse para instruir a una gran red neuronal para realizar una variedad de tareas de generación de texto. El mismo mes, la investigación de ImageGPT de la compañía mostró que redes neuronales similares podrían generar imágenes de alta fidelidad.
Para comenzar el nuevo año, DALL-E de OpenAI se basa en esto, «para mostrar que manipular conceptos visuales a través del lenguaje ahora está al alcance».
Derivado de un acrónimo del artista Salvador Dalí y WALL · E de Pixar, DALL · E es una versión de 12 mil millones de parámetros de GPT-3 entrenada para generar imágenes a partir de descripciones de texto usando un conjunto de datos de pares de texto e imagen. DALL · E cuenta con un conjunto diverso de capacidades, como crear versiones antropomorfizadas de animales y objetos, combinar conceptos no relacionados de manera plausible, representar texto y aplicar transformaciones a imágenes existentes.


Un modelo de lenguaje basado en transformadores, el vocabulario de DALL · E tiene tokens para conceptos de texto e imagen. Recibe texto e imágenes como un solo flujo de datos que contiene hasta 1280 tokens, y se entrena con la máxima probabilidad de generar tokens secuencialmente para generar imágenes desde cero. También puede regenerar regiones de imágenes existentes de manera coherente con el mensaje de texto.
OpenAI también presentó hoy CLIP (Contrastive Language-Image Pretraining), una red neuronal que aprende conceptos visuales de manera eficiente a partir de la supervisión del lenguaje natural. Los investigadores dicen que CLIP se puede aplicar a cualquier punto de referencia de clasificación visual simplemente proporcionando los nombres de las categorías visuales que se reconocerán, lo cual es similar a las capacidades de «disparo cero» de GPT-2 y -3.
Formada en una amplia variedad de imágenes con una amplia variedad de supervisión de lenguaje natural abundantemente disponible en Internet, la red puede recibir instrucciones en lenguaje natural para realizar una variedad de evaluaciones comparativas sin optimizar directamente el rendimiento de cada evaluación comparativa.
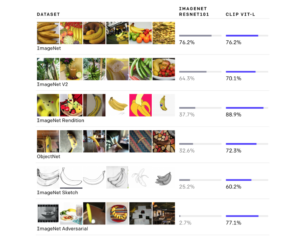
CLIP puede aprender de datos no filtrados, muy variados y con mucho ruido, y los modelos CLIP son significativamente más flexibles y generales que los modelos ImageNet existentes, dicen los investigadores. Los resultados de sus pruebas con CLIP muestran que el preentrenamiento agnóstico en el lenguaje natural a escala de Internet, que ha impulsado los avances recientes en PNL, también se puede aprovechar para mejorar el rendimiento del aprendizaje profundo en campos como la visión por computadora.
Fuente: SYNCED


