Un gran grupo de personas en el campo de la IA (incluidos Dan Hendrycks, Yoshua Bengio, Dawn Song, Max Tegmark, Eric Schmidt, Jaan Tallinn, Gary Marcus y otros) publicó un artículo que presenta un marco cuantificable para definir la Inteligencia Artificial General (IAG), con el objetivo de estandarizar el término y medir la brecha entre la IA actual y la cognición a nivel humano.
Las definiciones de IA general suelen ser confusas. El artículo argumenta que el término IA general actualmente funciona como una «meta en constante evolución». A medida que los sistemas de IA especializados dominan tareas que antes se creía que requerían intelecto humano, los criterios para la IA general cambian. Esta ambigüedad dificulta debates productivos sobre el progreso y oscurece la distancia real hasta alcanzar la inteligencia humana.
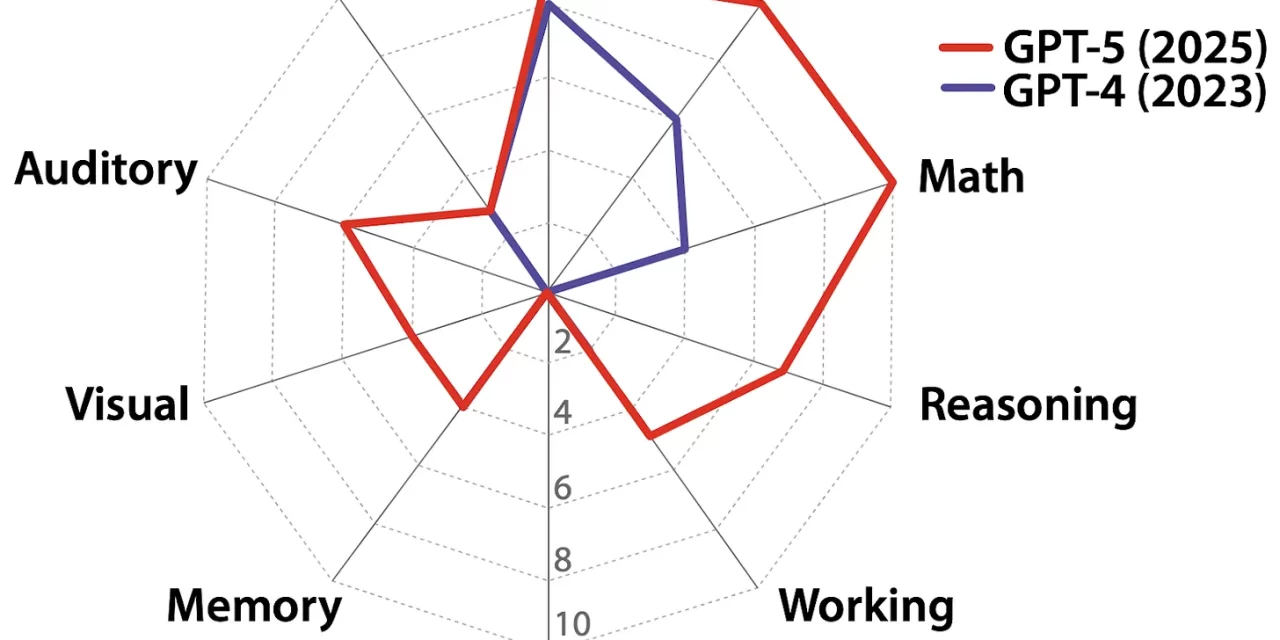
El marco se basa en la teoría. Los autores definen la IAG como «una IA que puede igualar o superar la versatilidad y la competencia cognitiva de un adulto con un buen nivel educativo». Para hacerlo operativo, basan su metodología en la teoría de Cattell-Horn-Carroll (CHC), el modelo de inteligencia humana más validado empíricamente. El marco adapta pruebas psicométricas humanas establecidas para evaluar sistemas de IA en diez dominios cognitivos fundamentales, lo que resulta en una «puntuación de IAG» estandarizada (0-100%).
Los modelos actuales presentan un perfil cognitivo irregular. La aplicación del marco revela capacidades muy desiguales. Si bien los modelos son competentes en áreas de conocimiento intensivo (como matemáticas o lectura/escritura), presentan deficiencias críticas en la maquinaria cognitiva fundamental.
El almacenamiento de memoria a largo plazo es el cuello de botella crítico. El déficit más significativo identificado es el almacenamiento de memoria a largo plazo, donde los modelos actuales tienen una puntuación cercana al 0 %. Esto genera una forma de «amnesia», que obliga a la IA a reaprender el contexto en cada interacción. El artículo señala que la dependencia de ventanas de contexto masivas (memoria de trabajo) es una «contorsión de capacidad» utilizada para compensar esta falta de memoria persistente.
El marco cuantifica la brecha hacia la IAG. Las puntuaciones resultantes buscan cuantificar concretamente tanto el rápido progreso como la considerable brecha restante hasta la IAG. El documento estima que el GPT-4 tiene una puntuación de IAG del 27% y el GPT-5 previsto (2025) del 58%.
Se puede acceder al artículo en agidefinition.ai .

